Paper in Stat: Stagewise Boosting Distributional Regression
Modern probabilistic forecasting requires modeling not only the mean of a response but its full distribution. Distributional regression, such as GAMLSS, provides this flexibility, yet reliable variable selection and stable estimation remain challenging in high-dimensional and complex settings. In our new paper, we introduce Stagewise Boosting Distributional Regression, a robust alternative to classical gradient boosting that overcomes vanishing gradient issues and improves scalability.
Key Contributions
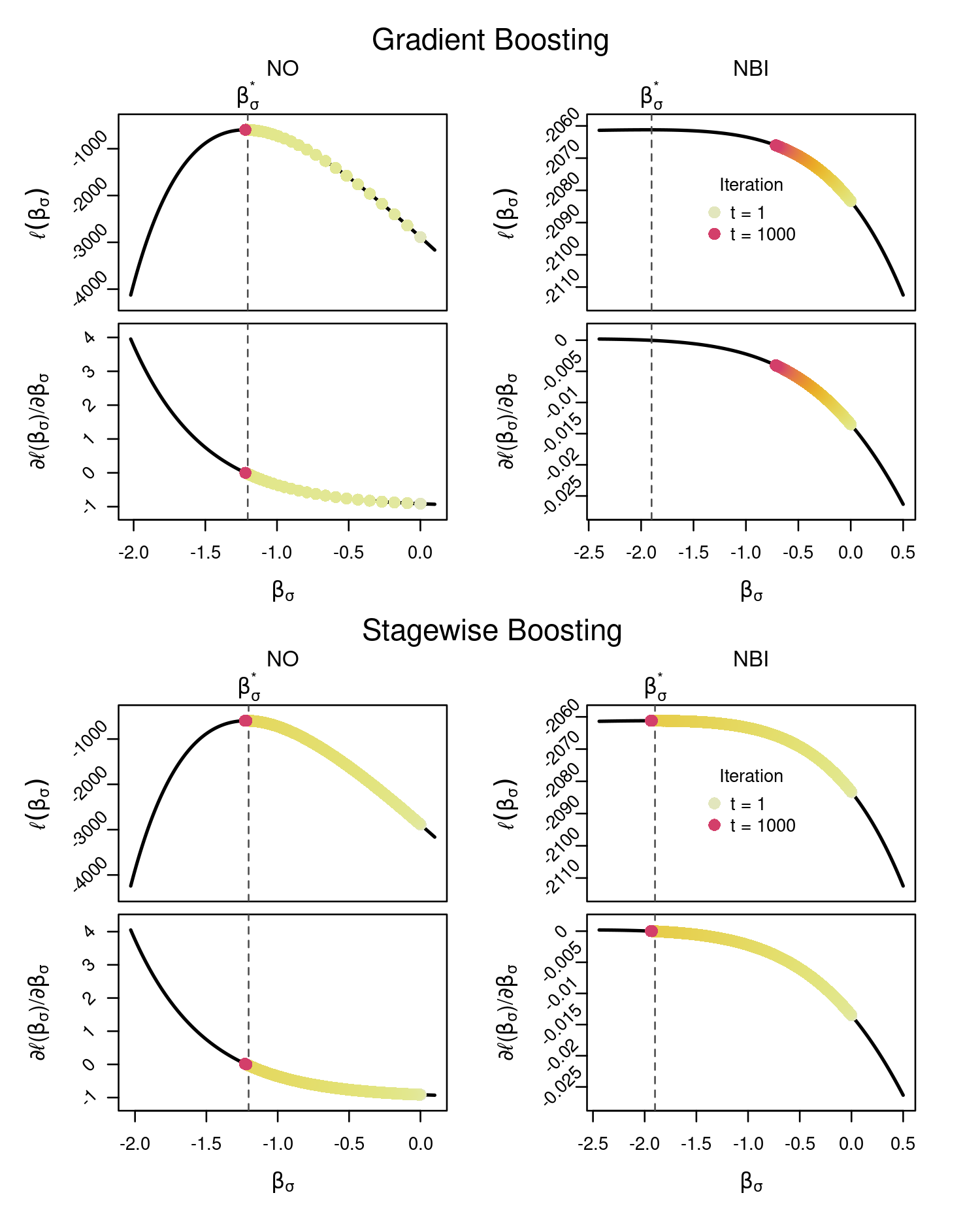
Semiconstant Stagewise Updates: We adapt forward stagewise regression to distributional regression using sign-based, semiconstant step updates. This prevents vanishing gradients, a common issue in complex distributions (e.g., zero-adjusted negative binomial models), and stabilizes learning.
Best-Subset Updating Across Distributional Parameters: Instead of updating only one parameter per iteration, the proposed method allows simultaneous updates of optimal subsets of distributional parameters, leading to more balanced and efficient estimation.
Correlation Filtering (CF) for Variable Selection: A novel correlation-based early stopping and selection criterion replaces costly cross-validation. CF effectively reduces false positives while maintaining strong predictive performance.
Batchwise Variants for Big Data:
A stochastic, batchwise extension enables scalable estimation for massive datasets, avoiding local optima and drastically reducing computation time.
Simulation Results
An extensive simulation study compares the proposed approach with state-of-the-art methods including gradient boosting, stability selection, and adaptive step-length boosting. Across normal, Gamma, and zero-adjusted negative binomial distributions, the proposed stagewise variants:
- Achieve lower false positive rates in variable selection.
- Provide competitive or superior predictive performance (CRPS).
- Avoid vanishing gradient problems in complex models.
- Are dramatically faster in large-scale settings (up to 100x faster in high-dimensional scenarios).
In challenging zero-inflated count models, classical gradient boosting struggles due to flat likelihood regions, whereas stagewise boosting remains stable and continues to identify relevant predictors.
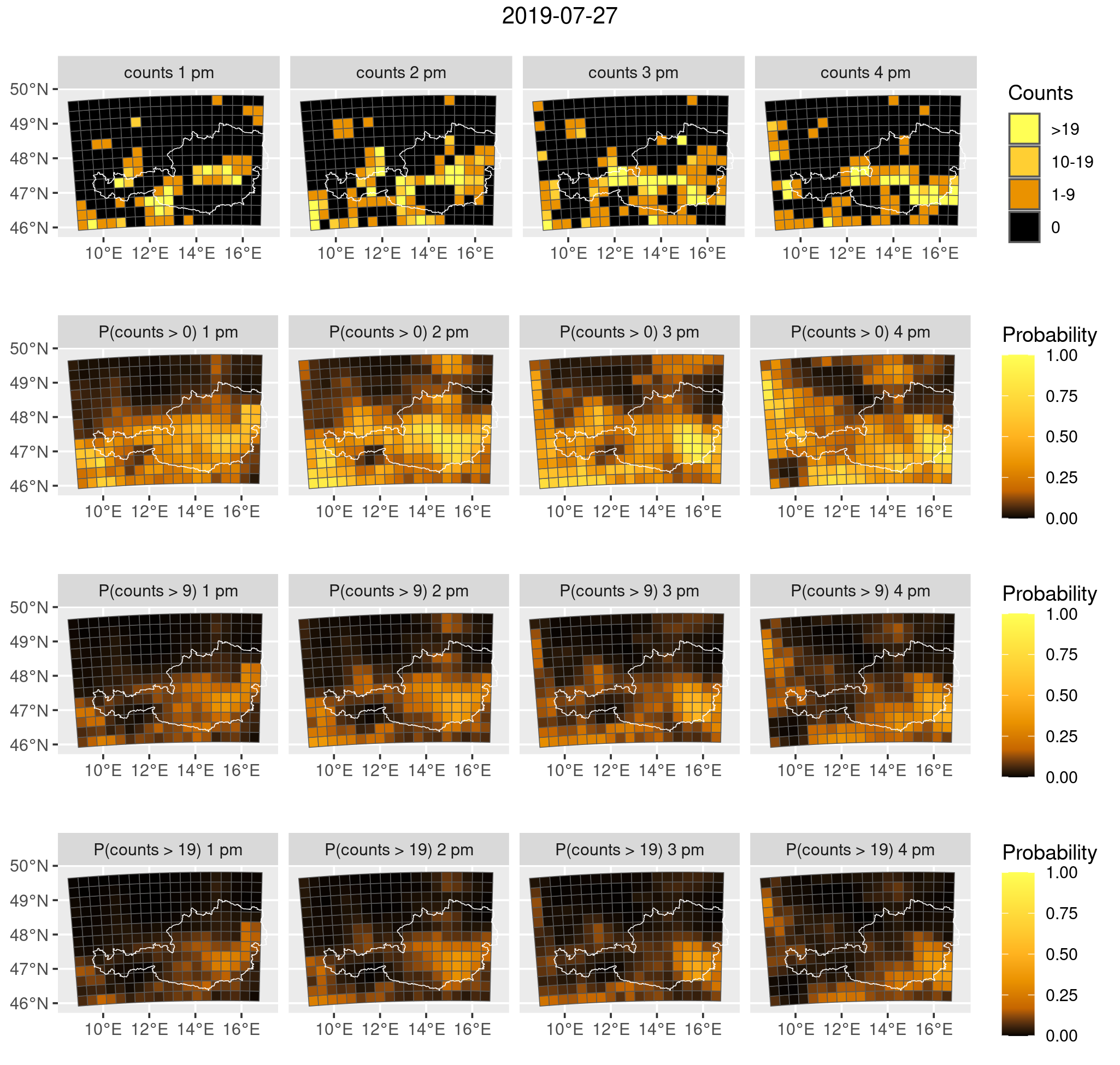
Application: Lightning Forecasting in Austria
To demonstrate scalability and practical relevance, we model hourly lightning counts across Austria using:
- 9.1 million observations,
- 672 candidate covariates (including transformations),
- a zero-adjusted negative binomial model.
The stagewise boosting algorithm successfully selects a balanced subset of meteorological predictors and delivers well-calibrated probabilistic forecasts. The approach efficiently handles rare-event data (only 2.65% positive counts) using a batchwise strategy with intercept correction.
The resulting model provides spatially resolved probabilistic forecasts of lightning intensity, illustrating the method’s suitability for large-scale environmental applications.
Enabling Scalable and Stable Distributional Regression
Distributional regression models are essential for modern probabilistic modeling in areas such as climate science, environmental risk assessment, epidemiology, and economics. However, classical boosting approaches can fail in complex or high-dimensional settings due to vanishing gradients and expensive tuning procedures.
Our stagewise boosting framework:
- Enhances numerical stability,
- Improves variable selection,
- Reduces computational burden,
- Scales to millions of observations,
- And maintains full probabilistic interpretability.
The methods are implemented in the R package stagewise, supporting all distributions from gamlss.dist.